Avago Announces PLX PEX9700 Series PCIe Switches: Focusing on Data Center and Racks
by Ian Cutress on May 12, 2015 12:30 PM EST- Posted in
- Enterprise
- Datacenter
- PLX
- Avago
- PCIe Switches
- PEX9700

One of the benefits of PCIe switches is that they are designed to be essentially transparent. In the consumer space, I would wager that 99% of the users do not even know if their system has one, let alone what it does or how it uses it. In most instances, PCIe switches help balance multiple PCIe configurations when a CPU and chipset supports multiple devices. More advanced situations might include multiplexing out PCIe lanes into multiple ports, allowing more devices to be used and expanding the limitations of the design. For example, the PEX8608 found in the ASRock C2750D4I which splits one PCIe x4 into four PCIe x1 lanes, allowing for four controllers as end points rather than just the one. Or back in 2012 we did a deep dive on the PLX8747 which splits 8 or 16 PCIe lanes into 32, through the use of a FIFO buffer and a mux, to allow for x8/x8/x8/x8 PCIe arrangements – the 8747 is still in use today in products like the ASRock X99 Extreme11 which uses two or the X99 WS-E/10G which has one.
Today’s announcement is from Avago, the company that purchased PLX back in June 2014, for a new range of PCIe switches focused on the data center and racks called the PEX9700 series. Part of the iterative improvements in PCIe switches should ultimately be latency and bandwidth, but there are several other features worth noting which from the outside might not be considered, such as the creation of a switching fabric.
Typically the PCIe switches we encounter in the consumer space use one upstream host to several downstream ports, and each port can have a series of PCIe lanes as bandwidth (so 4 ports can total 16 lanes, etc). This means there is one CPU host by which the PCIe switch can send the work from the downstream ports. The PLX9700 series is designed to communicate with several hosts at once, up to 24 at a time, allowing direct PCIe to PCIe communication, direct memory copy from one host to another, or shared downstream ports. Typically PCIe is a host-to-device topology, however the PEX9700 line allows multiple hosts to come together with an embedded DMA engine on each port to probe host memory for efficient transfer.

Unlike the previous PCIe switches from PLX, the new series also allows for downstream port isolation or containment, meaning that if one device downstream fails, the switch can isolate the data pathway and disable it until it is replaced. This can also be done manually as the PEX9700 series will also come with a management port which Avago states will use software modules for different control applications.
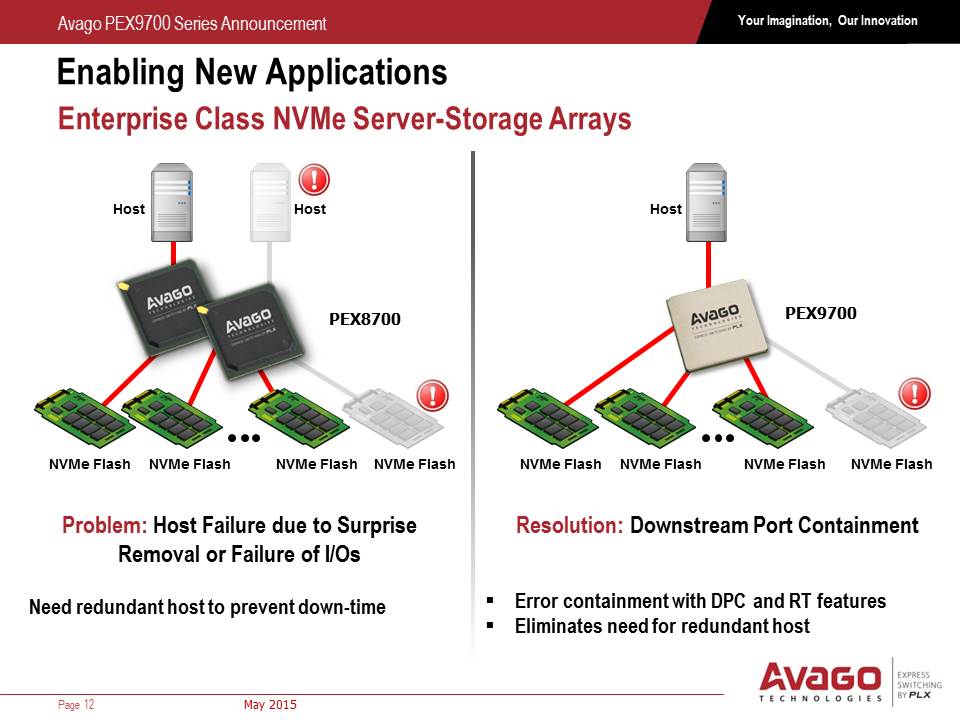
In the datacenter and within rack infrastructure, redundancy is a key feature to consider. As the PEX9700 switches allow host-to-host communication, it also allows control from multiple hosts, allowing one host to take over in the event of failure. The switches can also agglomerate and talk to each other, allowing for multiple execution routes especially with shared IO devices or in multiple socket systems for GPGPU use. Each switch will also have a level of hot-plugging and redundancy, allowing disabled devices to be removed, replaced and restarted. When it comes to IO, read requests mid-flow are fed back to the host as information on failed attempts, allowing instant reattempts when a replacement device is placed back into the system.

Avago is stating that the 9700 series will have seven products ranging from 5 to 24 ports (plus one for a management port) from 12 to 97 lanes. This also includes hot plug capability, tunneled connections, clock isolation and as mentioned before, downstream port isolation. These models are currently in full scale production, as per today’s announcement, using TSMC's 40nm process. In a briefing call today with Akber Kazmi, the Senior Product Line Manager for the PEX9700 series, he stated that validation of the designs took the best part of eight months, but that relevant tier one customers already have their hands on the silicon to develop their platforms.
For a lot of home users, this doesn’t mean that much. We might see one of these switches in a future consumer motherboard focused on dual-socket GPGPU, but the heart of these features lies in the ability to have multiple nodes access data quickly within a specific framework without having to invest in expensive technologies such as Infiniband. Avago is stating a 150ns latency per hop, with bandwidth limited ultimately by the upstream data path – the PCIe switch ultimately moves the bandwidth around to where it is most needed depending on downstream demand. The PEX9700 switches also allow for direct daisy chaining or as a cascading architecture through a backplane, reducing costs of big switches and allowing for a peak bandwidth between two switches of a full PCIe 3.0 x16 interface, allowing scaling up to 128 Gbps (minus overhead).
Personally, the GPGPU situation interests me a lot. When we have a dual socket system with each socket feeding multiple GPUs, with one PEX9700 switch per CPU (in this case, PEX9797) but interconnected, it allows GPUs on one socket to talk to GPUs on the other without having to go all the way back up to the CPU and across the QPI bus, which saves both latency and bandwidth, and each of the PCIe switches can be controlled.
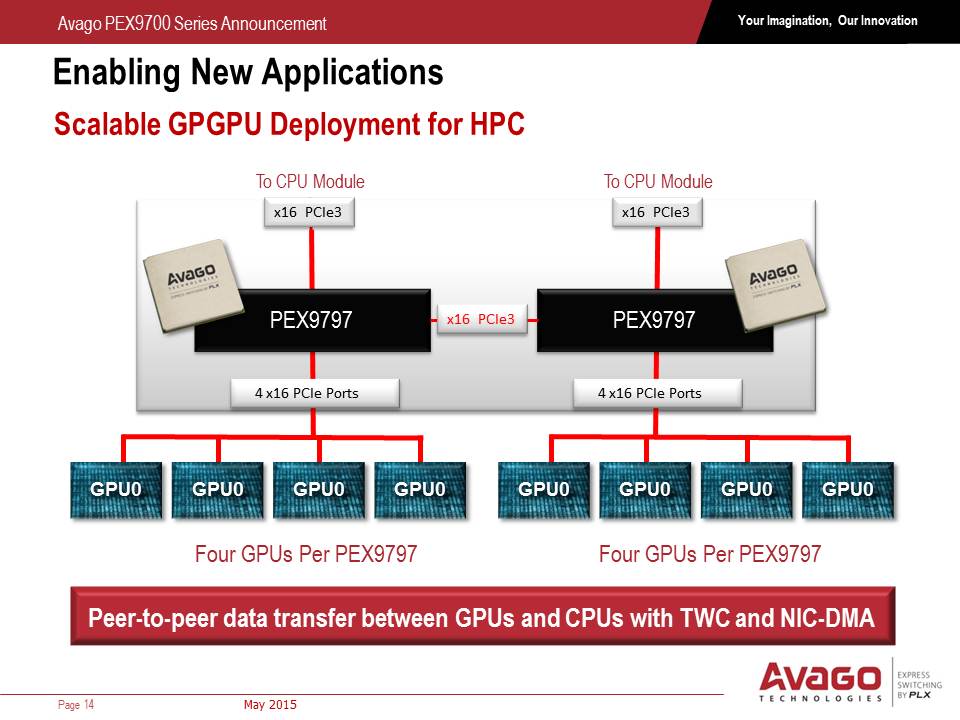
The PEX9700 series of switches bucks the status quo of requiring translation layers such as NICs or Infiniband for host-to-host-to-device communication and all inbetween, which is what Avago is hoping the product stack will accomplish. The main factors that Avago see the benefit include latency (fewer translation layers for communication), cost (scales up to 128 Gbps minus overhead), power (one PEX9700 chip has a 3W-25W power rating) and energy cost savings on top of that. On paper at least, the capabilities of the new range could potentially be disruptive. Hopefully we'll get to see one in the flesh at Computex from Avago's partners, and we'll update you when we do.
Source: Avago














12 Comments
View All Comments
JFish222 - Tuesday, May 12, 2015 - link
Admittedly to lazy to search myself, but I would be interested to know what physical cabling Avago are pushing to extend the PCIe fabric between external hosts, and what limitations the medium will impose. (I'm thinking of how this would compete with infiniband and NICs from a price/performance standpoint.)Ian Cutress - Tuesday, May 12, 2015 - link
Within a rack, you can just use a backplane. Technically you can go between racks with the right cards and optical cabling (which Avago also produce) without a translation layer, so I was told.MrSpadge - Tuesday, May 12, 2015 - link
Indeed, this could be very impressive! Consider communication between small tightly packed compute nodes. They don't need a regular LAN made for long distances, a quick high performance hop over a few 10 cm would be all they need, maybe even less depending on clever chassis design.This could also help AMD to combat NV link. It doesn't make the pipe into a single CPU any wider, but for a system with multiple GPUs and/or CPU sockets it could provide massive benefits.
MrSpadge - Tuesday, May 12, 2015 - link
And thanks for reporting such non-gaming topics, AT!olderkid - Tuesday, May 12, 2015 - link
Imagine marrying this to a Hyper Converged platform like Nutanix. Super fast i/o to multiple hosts for the distributed file system, lightning fast vmotion and storage vmotion. This is going to be some really cool stuff.Spirall - Tuesday, May 12, 2015 - link
My (long time) dream of turning a 1Gb/s home network (1Gb/s) into a "home HPC cluster" of about 10GB/s (with an external PEX9700 switch and some PCIe boards) may finally come true.zipcube - Wednesday, May 13, 2015 - link
you can do that now, 40gbit infiniband cards are going for less than $100 these days and you can find 36 port switches for $700. older 10 and 20gbit infiniband stuff is even cheaper. All of my home lab hosts are connected with 40gbit ibimmortalex - Thursday, May 14, 2015 - link
As far as I'm concerned and based on my tests, you can't push 20Gbps (not even close to 10Gpbs!) on a 20Gbit IB switch by using IP over Infiniband (IPoIB). In order to achieve 10/20/40 Gbps you need to bypass the kernel to avoid generating lots of system calls and taxing the CPU.You need to use the native Infiniband "verbs" programming interface to make full use of an Infiniband HCA and initiate data transfer from user space.
This will greatly limit the use for most apps, because they rely on the TCP/IP stack.
So yes, it's possible. But if you expect a plug-and-play scenario to achieve 10 or 20 Gbps from your PC to your home fileserver with low cost IB HCAs, Switches and cables - I don't think so.
zipcube - Thursday, May 14, 2015 - link
thats correct, your max theoretical with 40gbit ib is 32gbit usable. I'm usually getting in the ~26 gbit rangeusing SRP/iSER and NFS-RDMA based storage targets backed by either ssds or a conventional disk pool with a relatively large (400gb enterprise flash) buffer. I've seen higher rates with RDS/RDMA enabled apps though. I notice esxi 6 has a whole rdma framework builtin now so i'm looking forward to playing with that. My cards (mellanox connect-x 2) aren't supported in Windows 2012 for SMB Direct, so I haven't had a chance to mess with it much unfortunately.wishgranter - Wednesday, May 13, 2015 - link
Ok so that mean we will see a PCI-E riser cards eventually ??